Exception handling is the process of handling exceptional situations disrupting the normal flow of an application. This topic is fairly small and even newcomers to Java will come across exceptions pretty soon in their career, so knowing how you can handle exceptions is a must have even for people who consider themselves “junior” java developers.
Java provides a well thought out, object oriented way of handling exceptions. Let’s see the details in the following sections.
Exception handling overview
As I mentioned above, exception handling is the process of handling unexpected situations. These situations can happen for a lot of different reasons. For example, the programmer used nonexisting indexes on an array or tries to call methods on a nonexisting object, the database server could be down, or we could have lost network connection.
In Java, when a situation like this happens, an exception object is created and the JRE will try to find a piece of code that can handle the exception. This process is called throwing an exception. The exception object itself contains a lot of information about what happened. Where did the exception happen, what caused the exception and a complete stack trace that is basically the call hierarchy that led to this exception.
The logic for finding the piece of code that can handle the exception is pretty straightforward. It starts from the method where the exception is thrown and checks if that method can handle the exception. If it cannot handle it, it will go up the call hierarchy until it can find a suitable handler or the end of the call hierarchy is reached. When a handler is found we call it catching the exception. If no handler is found in the call chain, then the application will terminate and print information about the exception.
So now you have a general overview, let’s see the specifics.
Exception hierarchy
The first important part about exceptions is knowing what classes represent them in Java. The hierarchy looks like the following:
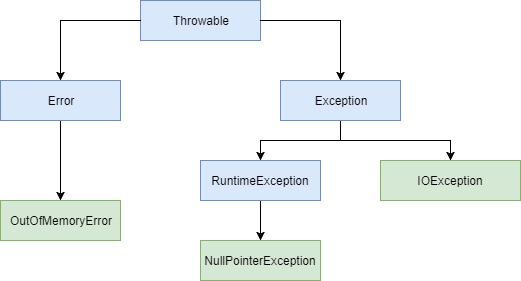
The starting point of the hierarchy is Throwable. All exceptions must be the descendant of this class. There are two direct child classes of Throwable: Error and Exception. Also, we have a special type of exception called a RuntimeException.
Exceptions that are of class Exception or any of its subclasses (except RuntimeException) are called checked exceptions because you have to do something (we’ll see later what this is) with them in your code if there is a possibility that they are thrown. On the other hand, exceptions that are instances of RuntimeException or one of its subclasses are called unchecked exceptions because you are not forced to deal with them in your code, but of course, you have the possibility. Errors are usually exceptions that the application cannot recover from.
Checked vs unchecked exceptions
There are two fundamentally different exceptions in Java: checked and unchecked exceptions.
Checked exceptions (Exception and its subclasses) are exceptions that usually happen because of some outside circumstance. For example, you are trying to open a file but someone has deleted it. Or you are trying to access a database, but the server is down. Most of these situations although not necessarily common, but has a pretty significant chance of happening at one point or another in the life of your application so you have to be prepared for them so your app can act gracefully in these cases.
If your code has a statement that can throw a checked exception, you have to do something with it. You have to either:
- Catch the exception and handle it in a
try-catch block.
- Declare the exception in the header of your method using the
throws keyword.
If you are not doing one of the above, you will be presented with a compilation error.
Unchecked exceptions (RuntimeException and its subclasses) are mostly caused by programming mistakes. For example, you are trying to access a nonexisting index in an array or you are trying to call a method on a null value. Because these can happen at almost any line in your code, handling them at every point would be really inefficient. This is why it is not mandatory to handle them. It would cause a lot of overhead and your code would be unreadable because of excess exception handling logic.
Of course, it won’t hurt if your application can handle these types of exceptions as well. A good practice to this is to handle them somewhere higher in the call hierarchy in a central place. This way, you only have the handler logic at one place but you are doing something with the exception and don’t let the situation escalate to a point where the user sees a stack trace.
The try-catch block
In Java, you can use the so called try-catch block to handle exceptions. This consists of two blocks. The try block contains the code that can throw the exception and the catch block contains code that will handle the exception. Let’s see a simple example.
public class CustomException extends Exception {
}
RiskyClass riskyClass = new RiskyClass();
try {
riskyClass.performRiskyAction();
} catch (CustomException e) {
// Handle the exception.
}
As you can see the try block contains some code that can throw an exception, and there is a catch block that will catch any CustomException thrown in the try block. For catch blocks it is mandatory to specify what exceptions it can catch.
Catching multiple exceptions
You can have multiple catch blocks if needed, like this:
try {
riskyClass.performRiskyAction();
} catch (CustomException e) {
// Handle the exception.
} catch (IOException e) {
// Handle the exception.
}
In case of multiple catch blocks, the JVM will start from the first one and goes until it finds one that can handle the exception. A catch block can handle an exception if the exception specified matches the thrown exception’s class or is a parent of it.
There is an important rule to the ordering of catch blocks. You have to start with the most specific and go towards the least specific. This is because if a less specific one would catch all the exceptions in the beginning, it would be impossible for the code to reach the remaining catch blocks. Here is an example of a correct ordering:
try {
riskyClass.performRiskyAction();
} catch (CustomException e) {
// Handle the exception.
} catch (IOException e) {
// Handle the exception.
} catch (Exception e) {
// Handle any Exception.
}
The first common superclass for CustomException and IOException is Exception so they can be in any order, but Exception must be specified after them because it is less specific.
Catching multiple exceptions in one block
Since Java 7, you can catch multiple exceptions in a single catch block by separating them with the pipe character. Here’s an example:
try {
riskyClass.performRiskyAction();
} catch (CustomException | IOException e) {
// Handle the exception.
} catch (Exception e) {
// Handle any Exception.
}
The only rule for the exceptions specified in the catch block is that none of them can be the other’s child/parent class as it would mean unnecessary code.
The finally block
You can extend the try-catch block with a finally block. Actually when you have a finally block, you can even omit the catch part.
In the finally block you can specify code that you would like to run regardless of whether an exception was thrown or not.
One of the most common cases is when you are opening a resource (like file stream) in the try block and you would like to be sure that it will be closed even if an exception happens. But that is not the only case. For example, the following code prints how long did the method take to complete in case an exception happens or not.
long startTime = System.currentTimeMillis();
try {
System.out.println("We are in try.");
} catch (Exception e) {
System.out.println("We are in catch.");
} finally {
System.out.println("We are in finally.");
System.out.println("Total time: " + (System.currentTimeMillis() - startTime) + " ms");
}
Remember, the finally block always executes except when:
- System.exit() is called.
- The JVM crashes.
- The try block never ends (e.g. endless loop).
Nested exception handlers
You can nest try-catch-finally blocks as deep as you would like. So you can have these blocks inside another try/catch/finally block.
Using try with resources
Before Java 7, it was pretty cumbersome to use some resources that needed to be closed after usage. A resource like this is a BufferedReader that uses a buffered input stream to read characters from for example a file. Let’s see an example how much code did you need to use it.
BufferedReader bufferedReader = null;
String line;
try {
bufferedReader = new BufferedReader(new FileReader("file.txt"));
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bufferedReader != null) {
bufferedReader.close();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
You can see that a good amount of code was needed just to handle the closing of BufferedReader to free up resources taken by it. You can see that this is boilerplate code as you have to do it the same way every time you are using a resource that needs to be closed.
Java 7 came to the rescue by introducing try with resources. It is basically a special version of the try block where you can specify the resource that you would like to use and the JVM will automatically close it for you.
String line;
try (BufferedReader bufferedReader = new BufferedReader(new FileReader("file.txt"))) {
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
As you can see, we could reduce the code to about half of its original size. You can specify as many resources as you want by separating them with semicolons. The only requirement for an object to be listed as a resource is that it has to implement the java.lang.AutoCloseable interface so the compiler can be sure that the classes used to implement a method know how to close the resource.
Declaring unhandled checked exceptions
If one of your methods can throw a checked exception and it is not handled in the method’s code, you have to declare it in the header of the method using the throws keyword.
public void testMethod() throws IOException {
String line;
try (BufferedReader bufferedReader = new BufferedReader(new FileReader("file.txt"))) {
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
}
}
It is also a good idea to document these exceptions in JavaDoc like this:
/**
* Test method.
*
* @throws IOException Thrown when the IO operation is unsuccessful.
*/
public void testMethod() throws IOException {
Throwing exceptions
Not only code that is coming from external libraries can throw exceptions. Using the throw keyword you can throw an exception any time you want. This is actually pretty often used for signaling to the caller that an exceptional situation has happened in your logic.
public void divide(int a, int b) {
if (b == 0) {
throw new IllegalArgumentException("You cannot divide by zero.");
}
// ...
}
public void performBusinessLogic(int input) throws CustomException {
if(input < 0) {
throw new CustomException("Cannot perform operation with input less than zero");
}
// ...
}
In the first example we are throwing an unchecked exception so it’s not declared in the method’s header. In the second example, a checked exception is thrown so we needed to declare it.
Wrapping exceptions
When you catch an exception it can often be a good idea to throw a new exception in the catch block. In these cases you should wrap the original exception in the new one, so when the new exception will be logged, the original one is logged as well.
try {
throw new UserNotFoundException("Cannot perform operation with input less than zero");
} catch (UserNotFoundException e) {
throw new OtherException("Other exception", e);
}
We called this constructor:
public UserNotFoundException(String message, Throwable cause) {
super(message, cause);
}
Custom exceptions
When you are throwing exceptions, those often should be custom exception classes made by you. Here are some examples:
public class UserNotFoundException extends Exception {
public UserNotFoundException() {
}
public UserNotFoundException(String message) {
super(message);
}
}
public class UserAlreadyExistsException extends Exception {
public UserAlreadyExistsException() {
}
public UserAlreadyExistsException(String message) {
super(message);
}
}
You can extend any of the existing exception classes (even yours) and create custom exception hierarchies.
Making and throwing custom exceptions allows you to be as specific as you want about the situation happening and you are able to handle the different exceptional cases in different ways.
Best practices
Logging
Properly logging the reason of the exceptions is one of the most important ways to keep your code as easily debuggable as possible. When you are catching an exception it is always a good idea to log a message stating the most concrete info that you know about the exception and you should also print the exception object itself as well. This will print the stack trace as well into the logs. It will come in very handy when someone wants to debug the code.
Of course, printing the exception information to the user is a bad idea. Usually, he won’t understand what is a NullPointerException for example and it can give away information to hackers. For users just print a friendly message that something went wrong and you’ll look into it.
Fail fast
If a method will throw an exception it is best if it throws as early as possible. So for example, if you have some conditions in your method that will result in an exception if not fulfilled, it’s best to check them as soon as you can, so the method won’t run unnecessarily for a longer period of time. This makes debugging easier as well.
Catch only when able to handle
You should only catch an exception when you can act on it properly. Just catching the exception and doing nothing will make debugging your application really hard when an exception happens.
Naming conventions
Your custom exceptions should be named in a way that they end in “Exception” like “CustomException”.